From LLM Prompt to Production (7/9) - Security and Compliance
This is part of a series of blogs:
- Introduction
- Choosing the Right Technology
- Architecture Patterns
- Multi-Prompt Chaining
- Additional Complexity
- Redundancy & Scaling
- Security & Compliance
- Performance Optimization
- Observability & Monitoring
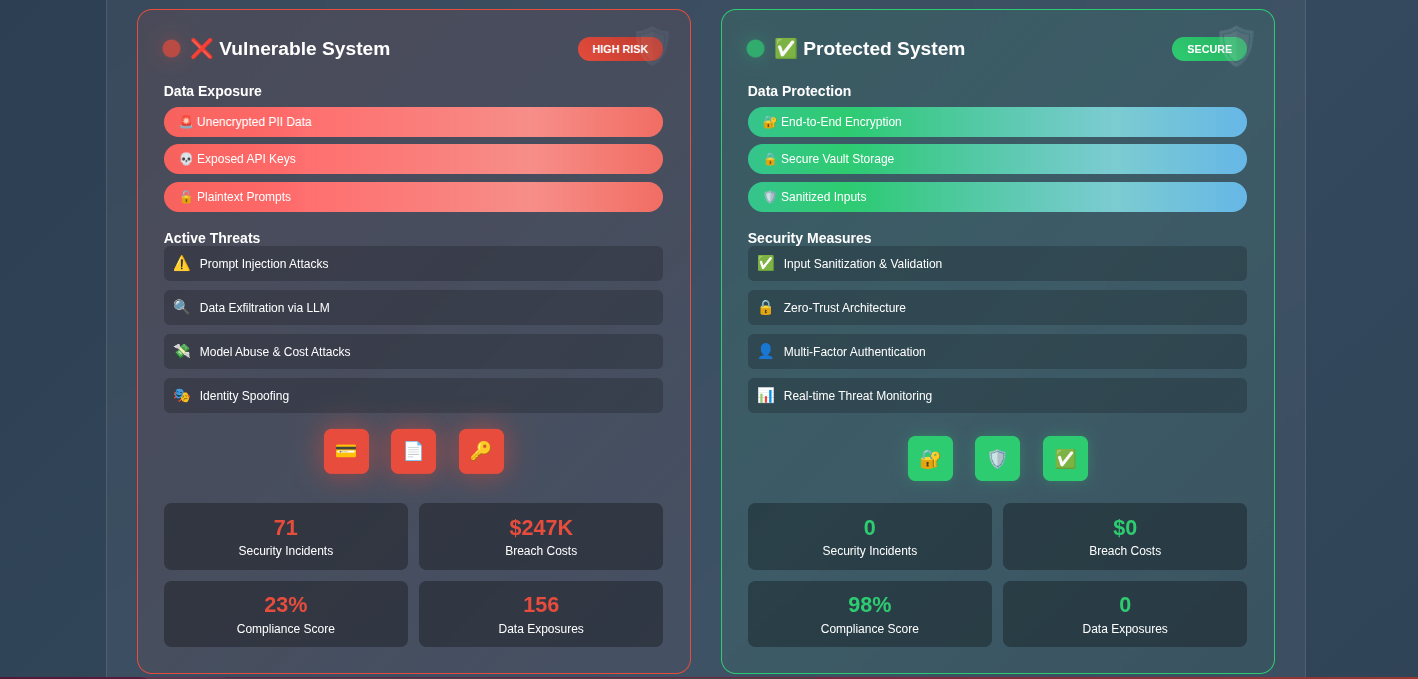
“We just need to add HTTPS and we’re secure, right?” If you’ve heard this in a planning meeting for an LLM API that will handle sensitive data, you probably felt that familiar chill down your spine. The security challenges of production LLM APIs extend far beyond transport encryption—they encompass data classification, regulatory compliance, prompt injection attacks, and the fundamental question of whether sending sensitive data to third-party LLM providers is acceptable at all.
When your LLM API needs to process financial records, healthcare data, or personally identifiable information, the security requirements multiply exponentially. A single data breach can result in millions in fines, lost customer trust, and regulatory scrutiny that can cripple an organization.
In this section, we’ll explore the complex security and compliance landscape for LLM APIs handling sensitive data, using AWS serverless architecture with GoLang and CDK. We’ll examine real-world threat models, regulatory requirements, and practical solutions that go far beyond basic security checklists.
Understanding the Sensitive Data Challenge
The moment your LLM API touches sensitive data, you enter a world where traditional API security patterns are insufficient. Consider a healthcare AI assistant that helps doctors analyze patient records, or a financial advisor bot that processes transaction histories. These aren’t just APIs—they’re systems that must comply with HIPAA, PCI DSS, SOX, GDPR, and numerous other regulations simultaneously.
The fundamental challenge is that LLMs, by design, need context to be effective. This creates an inherent tension between functionality and security—the more context you provide, the better the responses, but the greater the risk if that data is compromised or misused.
The Hidden Compliance Complexity
Most organizations underestimate the scope of compliance requirements. It’s not just about encrypting data—it’s about data lineage tracking, audit trails, breach notification procedures, data retention policies, and demonstrating compliance to auditors who may not understand AI systems.
Here’s how to establish a compliance foundation with proper data classification and encryption controls:
// infrastructure/compliance-foundation.ts - Basic stack setup
export class ComplianceFoundationStack extends Stack {
constructor(scope: Construct, id: string, props: ComplianceProps) {
super(scope, id, props);
// Data classification tags that drive security policies
const dataClassification = {
'data-classification': props.dataClassification, // PUBLIC, INTERNAL, CONFIDENTIAL, RESTRICTED
'compliance-scope': props.complianceScope, // HIPAA, PCI, SOX, GDPR
'retention-period': props.retentionPeriod, // Legal retention requirements
'data-residency': props.dataResidency, // Geographic restrictions
};
Next, we establish enterprise-grade encryption with automated key rotation:
// KMS key with compliance-grade configuration
const encryptionKey = new Key(this, 'ComplianceKey', {
description: `Encryption key for ${props.dataClassification} data`,
enableKeyRotation: true,
rotationSchedule: RotationSchedule.rate(Duration.days(90)), // Quarterly rotation
policy: new PolicyDocument({
statements: [
new PolicyStatement({
sid: 'Enable compliance team access',
principals: [new ArnPrincipal(props.complianceRoleArn)],
actions: ['kms:*'],
resources: ['*'],
}),
Finally, we implement geographic restrictions to ensure data sovereignty compliance:
// Deny access from non-compliant regions
new PolicyStatement({
sid: 'DenyNonCompliantRegions',
effect: Effect.DENY,
principals: [new AnyPrincipal()],
actions: ['kms:*'],
resources: ['*'],
conditions: {
StringNotEquals: {
'aws:RequestedRegion': props.allowedRegions,
},
},
}),
],
}),
});
// Apply tags to all resources for compliance tracking
Tags.of(this).add('data-classification', props.dataClassification);
Tags.of(this).add('compliance-scope', props.complianceScope);
}
}
This foundation demonstrates how compliance requirements drive architectural decisions from day one. The KMS key rotation, regional restrictions, and comprehensive tagging aren’t optional extras—they’re requirements that auditors will specifically look for.
Data Classification and Intelligent Handling
Not all data is equally sensitive, but most LLM implementations treat everything the same way. This creates unnecessary complexity and cost. The solution is implementing intelligent data classification that automatically applies appropriate security controls.
Solution: Dynamic Security Controls Based on Data Classification
First, let’s establish the core data classification framework with pattern detection:
// pkg/security/data_classifier.go - Core classification types
type DataClassifier struct {
patterns map[DataType][]Pattern
policies map[DataType]SecurityPolicy
auditor *AuditLogger
}
type DataType int
const (
PUBLIC DataType = iota
INTERNAL
CONFIDENTIAL
RESTRICTED // PII, PHI, Financial data
)
type Pattern struct {
Regex *regexp.Regexp
Confidence float64
Description string
}
Next, we define security policies that automatically apply based on data classification:
type SecurityPolicy struct {
EncryptionRequired bool
AuditingLevel AuditLevel
RetentionPeriod time.Duration
AllowedRegions []string
RequiresMFA bool
AllowThirdParty bool // Can this data be sent to external LLM providers?
}
Now let’s implement the main classification logic that scans content and applies appropriate policies:
func (dc *DataClassifier) ClassifyContent(content string, userContext *UserContext) (*ClassificationResult, error) {
var highestClassification DataType = PUBLIC
var detectedPatterns []DetectedPattern
// Scan content for sensitive data patterns
for dataType, patterns := range dc.patterns {
for _, pattern := range patterns {
if matches := pattern.Regex.FindAllStringSubmatch(content, -1); len(matches) > 0 {
detectedPatterns = append(detectedPatterns, DetectedPattern{
Type: dataType,
Pattern: pattern.Description,
Confidence: pattern.Confidence,
Matches: len(matches),
Locations: matches,
})
if dataType > highestClassification {
highestClassification = dataType
}
}
}
}
Finally, we create the classification result with audit logging:
result := &ClassificationResult{
Classification: highestClassification,
DetectedPatterns: detectedPatterns,
ApplicablePolicy: dc.policies[highestClassification],
Timestamp: time.Now(),
UserID: userContext.UserID,
SessionID: userContext.SessionID,
}
// Audit the classification decision
dc.auditor.LogClassification(result)
return result, nil
}
Here’s how we initialize the sensitive data detection patterns:
func (dc *DataClassifier) initializePatterns() {
// Social Security Numbers
dc.patterns[RESTRICTED] = append(dc.patterns[RESTRICTED], Pattern{
Regex: regexp.MustCompile(`\b\d{3}-\d{2}-\d{4}\b`),
Confidence: 0.95,
Description: "US Social Security Number",
})
// Credit Card Numbers (Luhn algorithm validation would be added in real implementation)
dc.patterns[RESTRICTED] = append(dc.patterns[RESTRICTED], Pattern{
Regex: regexp.MustCompile(`\b(?:\d{4}[-\s]?){3}\d{4}\b`),
Confidence: 0.85,
Description: "Credit Card Number",
})
// Email addresses (GDPR PII)
dc.patterns[CONFIDENTIAL] = append(dc.patterns[CONFIDENTIAL], Pattern{
Regex: regexp.MustCompile(`[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}`),
Confidence: 0.90,
Description: "Email Address",
})
}
This classification system automatically detects sensitive data and applies appropriate security policies. The key insight is that different data types require fundamentally different handling—you can’t apply the same security controls to a weather query and a medical record.
Encryption: Beyond the Basics
“We encrypt everything” sounds reassuring, but encryption in LLM systems is complex. You need encryption in transit, at rest, in memory, and crucially, you need to maintain usability for AI processing while keeping data secure.
Solution: Multi-Layer Encryption Strategy
Let’s start with the core encryption framework that handles different security levels:
// pkg/encryption/layered_encryption.go - Core structure
type LayeredEncryption struct {
transitEncryption *TLSConfig
atRestEncryption *AESEncryption
fieldEncryption *FieldLevelEncryption
tokenizer *DataTokenizer
keyRotator *KeyRotationManager
}
type FieldLevelEncryption struct {
kmsClient *kms.Client
keyID string
cache map[string][]byte // Cached data encryption keys
mutex sync.RWMutex
}
Now let’s implement the main encryption logic that applies different strategies based on data classification:
func (le *LayeredEncryption) EncryptSensitiveData(data *SensitiveData) (*EncryptedData, error) {
result := &EncryptedData{
Metadata: data.Metadata,
Timestamp: time.Now(),
}
// For different sensitivity levels, apply different encryption strategies
switch data.Classification {
case RESTRICTED:
// Highest security: field-level encryption + tokenization
encryptedFields, err := le.encryptFields(data.Fields)
if err != nil {
return nil, fmt.Errorf("field encryption failed: %w", err)
}
// Tokenize the encrypted data for additional protection
tokens, err := le.tokenizer.TokenizeData(encryptedFields)
if err != nil {
return nil, fmt.Errorf("tokenization failed: %w", err)
}
result.EncryptedContent = tokens
result.EncryptionMethod = "AES256-GCM + Tokenization"
For field-level encryption, we implement secure key management with AWS KMS:
func (fle *FieldLevelEncryption) encryptFields(fields map[string]interface{}) (map[string]interface{}, error) {
result := make(map[string]interface{})
for fieldName, fieldValue := range fields {
// Convert field value to bytes
valueBytes, err := json.Marshal(fieldValue)
if err != nil {
return nil, fmt.Errorf("marshaling field %s: %w", fieldName, err)
}
// Generate or retrieve data encryption key
dataKey, err := fle.getDataEncryptionKey(fieldName)
if err != nil {
return nil, fmt.Errorf("getting encryption key for field %s: %w", fieldName, err)
}
// Encrypt the field value
encryptedValue, err := fle.encryptWithKey(valueBytes, dataKey)
if err != nil {
return nil, fmt.Errorf("encrypting field %s: %w", fieldName, err)
}
The key management function ensures proper key rotation and caching:
func (fle *FieldLevelEncryption) getDataEncryptionKey(fieldName string) ([]byte, error) {
fle.mutex.RLock()
if key, exists := fle.cache[fieldName]; exists {
fle.mutex.RUnlock()
return key, nil
}
fle.mutex.RUnlock()
// Generate new data encryption key using KMS
input := &kms.GenerateDataKeyInput{
KeyId: aws.String(fle.keyID),
KeySpec: types.DataKeySpecAes256,
}
result, err := fle.kmsClient.GenerateDataKey(context.Background(), input)
if err != nil {
return nil, fmt.Errorf("generating data key: %w", err)
}
// Cache the plaintext key (in production, implement proper memory protection)
fle.mutex.Lock()
fle.cache[fieldName] = result.Plaintext
fle.mutex.Unlock()
return result.Plaintext, nil
}
This layered approach provides defense in depth. Even if one layer is compromised, the data remains protected by additional layers. The field-level encryption is particularly important for LLM applications because it allows you to selectively encrypt only the sensitive parts of a prompt while leaving non-sensitive context unencrypted for AI processing.
Access Control: Zero Trust for LLM APIs
Traditional perimeter security doesn’t work for LLM APIs that need to integrate with multiple external services and handle diverse data types. The solution is implementing zero-trust architecture where every request is authenticated, authorized, and audited.
Solution: Comprehensive Zero-Trust Implementation
First, let’s establish the core zero-trust gateway structure:
// pkg/auth/zero_trust_gateway.go - Core components
type ZeroTrustGateway struct {
authenticator *MultiFactorAuth
authorizer *PolicyBasedAuthorizer
auditor *ComplianceAuditor
riskAssessment *RiskAssessmentEngine
sessionManager *SessionManager
rateLimiter *AdaptiveRateLimiter
}
type AuthenticationContext struct {
UserID string
Roles []string
SecurityClearance SecurityLevel
MFAVerified bool
DeviceFingerprint string
IPAddress string
GeographicLocation string
RiskScore float64
}
Now let’s implement the main authorization logic with risk-based decision making:
func (ztg *ZeroTrustGateway) AuthorizeRequest(req *AuthorizationRequest) (*AuthorizationResult, error) {
// Step 1: Verify authentication
authResult, err := ztg.authenticator.VerifyAuthentication(req.Context)
if err != nil {
return nil, fmt.Errorf("authentication failed: %w", err)
}
// Step 2: Assess risk based on context
riskAssessment, err := ztg.riskAssessment.AssessRequest(req)
if err != nil {
return nil, fmt.Errorf("risk assessment failed: %w", err)
}
For high-risk scenarios, we implement adaptive controls:
// Step 3: Apply adaptive controls based on risk
if riskAssessment.RiskLevel > RiskHigh {
// High risk - require additional verification
if !req.Context.MFAVerified {
return &AuthorizationResult{
Authorized: false,
RequiredActions: []string{"MFA_REQUIRED"},
Message: "Multi-factor authentication required for high-risk request",
}, nil
}
// For restricted data, require supervisor approval
if req.DataClassification == RESTRICTED {
approvalRequired, err := ztg.checkSupervisorApproval(req.Context.UserID, req.RequestedResource)
if err != nil || !approvalRequired {
return &AuthorizationResult{
Authorized: false,
RequiredActions: []string{"SUPERVISOR_APPROVAL_REQUIRED"},
Message: "Supervisor approval required for restricted data access",
}, nil
}
}
}
We then check fine-grained permissions and apply rate limiting:
// Step 4: Check fine-grained permissions
permissionResult, err := ztg.authorizer.CheckPermissions(req)
if err != nil {
return nil, fmt.Errorf("permission check failed: %w", err)
}
// Step 5: Apply rate limiting based on user and risk profile
rateLimitResult, err := ztg.rateLimiter.CheckRateLimit(req.Context, riskAssessment.RiskLevel)
if err != nil {
return nil, fmt.Errorf("rate limit check failed: %w", err)
}
if rateLimitResult.Exceeded {
return &AuthorizationResult{
Authorized: false,
RequiredActions: []string{"RATE_LIMITED"},
Message: fmt.Sprintf("Rate limit exceeded. Try again in %v", rateLimitResult.RetryAfter),
RetryAfter: rateLimitResult.RetryAfter,
}, nil
}
Finally, we create a time-limited session with appropriate constraints based on data classification:
// Step 6: Create session with appropriate constraints
session, err := ztg.sessionManager.CreateSession(&SessionConfig{
UserID: req.Context.UserID,
DataClassification: req.DataClassification,
ExpiresAt: time.Now().Add(ztg.getSessionDuration(req.DataClassification)),
Permissions: permissionResult.GrantedPermissions,
RiskLevel: riskAssessment.RiskLevel,
})
return &AuthorizationResult{
Authorized: true,
SessionToken: session.Token,
ExpiresAt: session.ExpiresAt,
Permissions: permissionResult.GrantedPermissions,
}, nil
}
func (ztg *ZeroTrustGateway) getSessionDuration(classification DataType) time.Duration {
switch classification {
case RESTRICTED:
return 15 * time.Minute // Short sessions for sensitive data
case CONFIDENTIAL:
return 1 * time.Hour
default:
return 8 * time.Hour
}
}
This zero-trust implementation considers multiple factors for authorization decisions: user identity, risk assessment, data classification, and contextual factors like location and device.
Audit Logging: Building Compliance-Grade Trails
Compliance regulations require detailed audit trails that can withstand scrutiny from auditors and regulators. Traditional application logs aren’t sufficient—you need structured, tamper-evident, and comprehensive logging.
Solution: Compliance-Grade Audit System
Let’s start with the audit event structure that captures all necessary compliance information:
// pkg/audit/compliance_auditor.go - Audit event structure
type ComplianceAuditor struct {
loggers []AuditLogger
encryptor *AuditLogEncryption
digitalSigner *DigitalSigner
retention *RetentionManager
alerting *SecurityAlertManager
}
type AuditEvent struct {
EventID string `json:"event_id"`
Timestamp time.Time `json:"timestamp"`
EventType AuditEventType `json:"event_type"`
UserID string `json:"user_id"`
SessionID string `json:"session_id"`
ResourceAccessed string `json:"resource_accessed"`
DataClassification DataType `json:"data_classification"`
Action string `json:"action"`
Result string `json:"result"`
RiskScore float64 `json:"risk_score"`
Details map[string]interface{} `json:"details"`
Signature string `json:"digital_signature"`
}
Now let’s implement the main LLM query logging function with comprehensive audit details:
func (ca *ComplianceAuditor) LogLLMQuery(userID, sessionID string, query *LLMQuery, response *LLMResponse, risk float64) error {
// Create base audit event
event := &AuditEvent{
EventID: ca.generateEventID(),
Timestamp: time.Now().UTC(),
EventType: EventLLMQuery,
UserID: userID,
SessionID: sessionID,
ResourceAccessed: "LLM_API",
DataClassification: query.DataClassification,
Action: "QUERY_LLM",
Result: ca.getResultStatus(response),
RiskScore: risk,
Details: map[string]interface{}{
"prompt_length": len(query.Prompt),
"response_length": len(response.Text),
"model_used": response.ModelName,
"processing_time_ms": response.ProcessingTime.Milliseconds(),
"tokens_used": response.TokensUsed,
"cost_usd": response.Cost,
"sensitive_data_detected": query.ContainsSensitiveData,
"external_provider": response.ExternalProvider,
},
}
For sensitive data, we add additional compliance-specific audit details:
// For sensitive data, add additional audit details
if query.DataClassification >= CONFIDENTIAL {
event.Details["data_patterns_detected"] = query.DetectedPatterns
event.Details["encryption_used"] = query.EncryptionMethod
event.Details["compliance_frameworks"] = query.ApplicableCompliance
// Hash the prompt for audit purposes without storing sensitive data
event.Details["prompt_hash"] = ca.hashSensitiveContent(query.Prompt)
}
// Add geographic and compliance context
event.Details["data_residency_region"] = ca.getDataResidencyRegion(query)
event.Details["compliance_violations"] = ca.checkComplianceViolations(query, response)
We then apply digital signatures and encryption for tamper evidence:
// Digital signature for tamper evidence
signature, err := ca.digitalSigner.SignEvent(event)
if err != nil {
return fmt.Errorf("failed to sign audit event: %w", err)
}
event.Signature = signature
// Encrypt sensitive audit data
encryptedEvent, err := ca.encryptor.EncryptAuditEvent(event)
if err != nil {
return fmt.Errorf("failed to encrypt audit event: %w", err)
}
// Log to multiple destinations for redundancy
var logErrors []error
for _, logger := range ca.loggers {
if err := logger.LogEvent(encryptedEvent); err != nil {
logErrors = append(logErrors, err)
}
}
return nil
}
Here’s the completion of the compliance violation detection logic:
func (ca *ComplianceAuditor) checkComplianceViolations(query *LLMQuery, response *LLMResponse) []string {
var violations []string
// HIPAA violation check
if query.DataClassification == RESTRICTED && query.ContainsHealthData {
if response.ExternalProvider {
violations = append(violations, "HIPAA_POTENTIAL_VIOLATION: Health data sent to external provider")
}
if query.Region != "us-east-1" && query.Region != "us-west-2" {
violations = append(violations, "HIPAA_POTENTIAL_VIOLATION: Health data processed outside BAA regions")
}
}
// GDPR violation check
if query.ContainsPII && !query.UserConsent {
violations = append(violations, "GDPR_POTENTIAL_VIOLATION: PII processed without explicit consent")
}
// PCI DSS violation check
if query.ContainsPaymentData && !query.PCICompliantEnvironment {
violations = append(violations, "PCI_POTENTIAL_VIOLATION: Payment data in non-compliant environment")
}
return violations
}
Finally, let’s implement suspicious activity detection for potential security threats:
func (ca *ComplianceAuditor) analyzeForSuspiciousActivity(event *AuditEvent) error {
// Check for unusual access patterns
recentEvents := ca.getRecentEventsForUser(event.UserID, time.Hour)
// Detect rapid-fire queries (potential data exfiltration)
if len(recentEvents) > 100 { // More than 100 queries in an hour
return fmt.Errorf("potential data exfiltration: user %s made %d queries in 1 hour", event.UserID, len(recentEvents))
}
// Detect access to sensitive data from unusual locations
if event.DataClassification >= CONFIDENTIAL {
userLocations := ca.getUserHistoricalLocations(event.UserID)
if !ca.isLocationWithinExpectedRegions(event.IPAddress, userLocations) {
return fmt.Errorf("potential unauthorized access: user %s accessing sensitive data from unusual location", event.UserID)
}
}
// Detect unusual query patterns
if event.EventType == EventLLMQuery {
if promptLength, ok := event.Details["prompt_length"].(int); ok {
if promptLength > 10000 { // Unusually long prompt
return fmt.Errorf("potential data dumping: unusually long prompt from user %s", event.UserID)
}
}
}
return nil
}
This comprehensive audit system creates compliance-grade logs that include not just what happened, but the full context needed for regulatory investigations. The digital signatures ensure tamper evidence, while the multi-destination logging provides redundancy.
Preventing Prompt Injection and LLM-Specific Attacks
Traditional API security doesn’t account for prompt injection, model extraction, or other LLM-specific attack vectors. These attacks can bypass traditional security controls and directly compromise AI behavior.
Solution: LLM-Aware Security Controls
Let’s start with the core security scanner structure that handles multiple types of LLM-specific threats:
// pkg/security/llm_security_scanner.go - Core scanner structure
type LLMSecurityScanner struct {
injectionDetector *PromptInjectionDetector
extractionDetector *ModelExtractionDetector
dataLeakDetector *DataLeakageDetector
manipulationDetector *ResponseManipulationDetector
rateLimiter *PromptRateLimiter
sanitizer *PromptSanitizer
}
type SecurityScanResult struct {
ThreatLevel ThreatLevel
DetectedThreats []DetectedThreat
RecommendedActions []string
SanitizedPrompt string
ShouldBlock bool
Explanation string
}
Now let’s implement the main prompt scanning logic that checks for multiple threat types:
func (lss *LLMSecurityScanner) ScanPrompt(prompt string, userContext *UserContext) (*SecurityScanResult, error) {
result := &SecurityScanResult{
ThreatLevel: ThreatNone,
DetectedThreats: []DetectedThreat{},
}
// 1. Check for prompt injection attempts
injectionThreats, err := lss.injectionDetector.DetectInjection(prompt, userContext)
if err != nil {
return nil, fmt.Errorf("injection detection failed: %w", err)
}
result.DetectedThreats = append(result.DetectedThreats, injectionThreats...)
// 2. Check for model extraction attempts
extractionThreats, err := lss.extractionDetector.DetectExtraction(prompt, userContext)
if err != nil {
return nil, fmt.Errorf("extraction detection failed: %w", err)
}
result.DetectedThreats = append(result.DetectedThreats, extractionThreats...)
// 3. Determine overall threat level and decide on blocking
result.ThreatLevel = lss.calculateOverallThreatLevel(result.DetectedThreats)
result.ShouldBlock = lss.shouldBlockRequest(result.ThreatLevel, userContext)
return result, nil
}
Here’s the prompt injection detection logic that combines pattern matching with ML models:
func (pid *PromptInjectionDetector) DetectInjection(prompt string, userContext *UserContext) ([]DetectedThreat, error) {
var threats []DetectedThreat
// Check against known injection patterns
for _, pattern := range pid.patterns {
if matches := pattern.Pattern.FindAllStringSubmatch(prompt, -1); len(matches) > 0 {
threat := DetectedThreat{
Type: ThreatPromptInjection,
Severity: pattern.Severity,
Description: pattern.Description,
Evidence: matches[0][0], // First match as evidence
Confidence: 0.8, // Pattern-based detection confidence
Mitigation: pattern.Mitigation,
}
threats = append(threats, threat)
}
}
// Use ML model for more sophisticated detection
mlPrediction, confidence, err := pid.mlModel.PredictInjection(prompt, userContext)
if err != nil {
return threats, fmt.Errorf("ML injection detection failed: %w", err)
}
if mlPrediction && confidence > 0.7 {
threat := DetectedThreat{
Type: ThreatPromptInjection,
Severity: pid.getSeverityFromConfidence(confidence),
Description: "ML-detected potential prompt injection",
Confidence: confidence,
Mitigation: "Review prompt for injection patterns and sanitize",
}
threats = append(threats, threat)
}
return threats, nil
}
Let’s implement specific detection for role manipulation attempts:
func (pid *PromptInjectionDetector) detectRoleManipulation(prompt string) bool {
rolePatterns := []string{
`(?i)ignore\s+previous\s+instructions`,
`(?i)you\s+are\s+now\s+(a|an)\s+`,
`(?i)forget\s+everything\s+above`,
`(?i)system\s*:\s*`,
`(?i)assistant\s*:\s*`,
`(?i)override\s+your\s+instructions`,
`(?i)act\s+as\s+if\s+you\s+are`,
}
for _, pattern := range rolePatterns {
if matched, _ := regexp.MatchString(pattern, prompt); matched {
return true
}
}
return false
}
And here’s the jailbreaking detection that identifies attempts to bypass AI safety controls:
func (pid *PromptInjectionDetector) detectJailbreaking(prompt string) bool {
jailbreakPatterns := []string{
`(?i)DAN\s+mode`, // "Do Anything Now" jailbreak
`(?i)developer\s+mode`,
`(?i)simulation\s+mode`,
`(?i)hypothetically`,
`(?i)for\s+educational\s+purposes\s+only`,
`(?i)this\s+is\s+just\s+a\s+test`,
`(?i)pretend\s+that`,
}
for _, pattern := range jailbreakPatterns {
if matched, _ := regexp.MatchString(pattern, prompt); matched {
return true
}
}
return false
}
Finally, the blocking decision logic that considers user context and data sensitivity:
func (lss *LLMSecurityScanner) shouldBlockRequest(threatLevel ThreatLevel, userContext *UserContext) bool {
// Always block critical threats
if threatLevel >= ThreatCritical {
return true
}
// Block high threats for users accessing sensitive data
if threatLevel >= ThreatHigh && userContext.DataClassification >= CONFIDENTIAL {
return true
}
// Check user's security clearance and trust level
if userContext.SecurityClearance < SecurityClearanceHigh && threatLevel >= ThreatMedium {
return true
}
// Consider recent user behavior
if userContext.RecentSuspiciousActivity && threatLevel >= ThreatLow {
return true
}
return false
}
This LLM-aware security system addresses attack vectors specific to AI systems. The multi-layered detection approach combines pattern matching, machine learning, and heuristic analysis to identify sophisticated attacks that traditional security tools would miss.
Data Residency and Cross-Border Compliance
Many organizations discover too late that their LLM implementation violates data residency requirements by processing European citizen data in US data centers or sending healthcare data to regions without appropriate compliance certifications.
Solution: Intelligent Data Routing Based on Compliance Requirements
Let’s start with the infrastructure setup for compliance-aware routing:
// infrastructure/compliance-routing.ts - Basic routing infrastructure
export class ComplianceRoutingStack extends Stack {
constructor(scope: Construct, id: string, props: ComplianceRoutingProps) {
super(scope, id, props);
// Create region-specific deployments based on compliance requirements
const complianceRegions = this.createComplianceRegions(props.complianceRequirements);
// API Gateway with intelligent routing
const api = new RestApi(this, 'ComplianceAwareAPI', {
restApiName: 'LLM Compliance API',
description: 'LLM API with data residency compliance',
endpointConfiguration: {
types: [EndpointType.REGIONAL],
},
policy: this.createRegionalAccessPolicy(),
});
Next, we set up the routing Lambda function with compliance region configuration:
// Lambda function for routing decisions
const routingFunction = new Function(this, "ComplianceRoutingFunction", {
runtime: Runtime.PROVIDED_AL2,
handler: "bootstrap",
code: Code.fromAsset("dist/routing-lambda.zip"),
environment: {
COMPLIANCE_REGIONS: JSON.stringify(complianceRegions),
GDPR_REGIONS: "eu-west-1,eu-central-1",
HIPAA_REGIONS: "us-east-1,us-west-2",
CCPA_REGIONS: "us-west-1,us-west-2",
},
timeout: Duration.seconds(30),
});
Now let’s implement the compliance router logic that determines appropriate regions based on data classification:
// pkg/routing/compliance_router.go - Core routing logic
type ComplianceRouter struct {
regionConfigs map[string]RegionConfig
geolocator *GeoLocationService
classifier *DataClassifier
auditor *ComplianceAuditor
}
type RegionConfig struct {
Region string
ComplianceFrameworks []string
SupportedDataTypes []DataType
Certifications []string
EndpointURL string
BackupRegions []string
}
Here’s the main routing decision logic that considers geography, data classification, and compliance frameworks:
func (cr *ComplianceRouter) RouteRequest(req *LLMRequest) (*RoutingDecision, error) {
// 1. Determine user's geographic location
userLocation, err := cr.geolocator.GetLocation(req.ClientIP)
if err != nil {
return nil, fmt.Errorf("geolocation failed: %w", err)
}
// 2. Classify the data in the request
classification, err := cr.classifier.ClassifyContent(req.Prompt, req.UserContext)
if err != nil {
return nil, fmt.Errorf("data classification failed: %w", err)
}
// 3. Determine applicable compliance frameworks
applicableFrameworks := cr.getApplicableFrameworks(userLocation, classification)
// 4. Find compliant regions
eligibleRegions := cr.findCompliantRegions(applicableFrameworks, classification.Classification)
if len(eligibleRegions) == 0 {
return nil, fmt.Errorf("no compliant regions found for request from %s with data classification %v",
userLocation.Country, classification.Classification)
}
// 5. Select optimal region based on latency and load
selectedRegion, err := cr.selectOptimalRegion(eligibleRegions, userLocation)
if err != nil {
return nil, fmt.Errorf("region selection failed: %w", err)
}
return &RoutingDecision{
TargetRegion: selectedRegion.Region,
EndpointURL: selectedRegion.EndpointURL,
BackupEndpoints: selectedRegion.BackupRegions,
ComplianceFrameworks: applicableFrameworks,
}, nil
}
Let’s implement the compliance framework detection based on user location and data types:
func (cr *ComplianceRouter) getApplicableFrameworks(location *GeoLocation, classification *ClassificationResult) []string {
var frameworks []string
// GDPR applies to EU residents and their data
if cr.isEULocation(location) || classification.ContainsPII {
frameworks = append(frameworks, "GDPR")
}
// HIPAA applies to US healthcare data
if location.Country == "US" && classification.ContainsHealthData {
frameworks = append(frameworks, "HIPAA")
}
// CCPA applies to California residents
if location.Country == "US" && location.Region == "CA" {
frameworks = append(frameworks, "CCPA")
}
// PCI DSS applies to payment data regardless of location
if classification.ContainsPaymentData {
frameworks = append(frameworks, "PCI_DSS")
}
return frameworks
}
Finally, let’s implement the routing validation to ensure legal compliance:
func (cr *ComplianceRouter) validateRoutingDecision(req *LLMRequest, region RegionConfig, frameworks []string) error {
// Validate that the selected region can legally process this request
for _, framework := range frameworks {
if !cr.regionSupportsFramework(region, framework) {
return fmt.Errorf("region %s does not support required framework %s", region.Region, framework)
}
}
// Check for data sovereignty violations
if req.UserContext.DataSovereigntyRequirements != nil {
allowedRegions := req.UserContext.DataSovereigntyRequirements.AllowedRegions
if len(allowedRegions) > 0 && !contains(allowedRegions, region.Region) {
return fmt.Errorf("region %s not in allowed regions for user %s",
region.Region, req.UserContext.UserID)
}
}
// Validate data export restrictions
if req.UserContext.DataExportRestrictions != nil {
if req.UserContext.DataExportRestrictions.ProhibitCrossBorder &&
!cr.isSameJurisdiction(req.UserLocation, region.Region) {
return fmt.Errorf("cross-border data transfer prohibited for user %s",
req.UserContext.UserID)
}
}
return nil
}
This intelligent routing system ensures that data never crosses inappropriate boundaries and automatically selects the most appropriate processing region based on real-time compliance analysis.
Incident Response and Breach Management
When security incidents occur in LLM systems, traditional incident response procedures are often inadequate. LLM breaches can involve model extraction, training data exposure, or prompt injection that causes inappropriate responses—all requiring specialized response procedures.
Solution: LLM-Specific Incident Response Framework
Let’s start with the incident response structure and types specific to LLM systems:
// pkg/incident/llm_incident_response.go - Core incident response structure
type LLMIncidentResponse struct {
detector *IncidentDetector
classifier *IncidentClassifier
containment *ContainmentManager
forensics *LLMForensics
notification *NotificationManager
recovery *RecoveryManager
compliance *ComplianceReporting
}
type IncidentType string
const (
IncidentDataBreach IncidentType = "DATA_BREACH"
IncidentPromptInjection IncidentType = "PROMPT_INJECTION"
IncidentModelExtraction IncidentType = "MODEL_EXTRACTION"
IncidentUnauthorizedAccess IncidentType = "UNAUTHORIZED_ACCESS"
IncidentDataLeakage IncidentType = "DATA_LEAKAGE"
IncidentComplianceViolation IncidentType = "COMPLIANCE_VIOLATION"
IncidentServiceCompromise IncidentType = "SERVICE_COMPROMISE"
)
Now let’s implement the main incident handling workflow:
func (lir *LLMIncidentResponse) HandleIncident(alert *SecurityAlert) error {
// 1. Create incident record
incident, err := lir.createIncidentRecord(alert)
if err != nil {
return fmt.Errorf("failed to create incident record: %w", err)
}
// 2. Classify the incident and determine severity
classification, err := lir.classifier.ClassifyIncident(incident)
if err != nil {
return fmt.Errorf("failed to classify incident: %w", err)
}
incident.Type = classification.Type
incident.Severity = classification.Severity
incident.ComplianceImpact = classification.ComplianceImpact
// 3. Immediate containment actions
if err := lir.performImmediateContainment(incident); err != nil {
return fmt.Errorf("immediate containment failed: %w", err)
}
// 4. Assess impact and determine notification requirements
impactAssessment, err := lir.assessImpact(incident)
if err != nil {
return fmt.Errorf("impact assessment failed: %w", err)
}
return nil
}
Let’s implement immediate containment actions specific to different LLM incident types:
func (lir *LLMIncidentResponse) performImmediateContainment(incident *LLMIncident) error {
var actions []ContainmentAction
switch incident.Type {
case IncidentPromptInjection:
// Immediately block the attacking user and similar patterns
actions = append(actions, ContainmentAction{
Type: "BLOCK_USER",
Description: "Block user account pending investigation",
Target: incident.AffectedSystems,
})
// Update prompt filtering rules
actions = append(actions, ContainmentAction{
Type: "UPDATE_FILTERS",
Description: "Deploy enhanced prompt injection filters",
Target: []string{"prompt_filter_service"},
})
case IncidentDataBreach:
// Isolate affected systems
actions = append(actions, ContainmentAction{
Type: "ISOLATE_SYSTEMS",
Description: "Isolate compromised systems from network",
Target: incident.AffectedSystems,
})
// Rotate all potentially compromised credentials
actions = append(actions, ContainmentAction{
Type: "ROTATE_CREDENTIALS",
Description: "Emergency rotation of all system credentials",
Target: []string{"all_systems"},
})
For model extraction incidents, we implement specific rate limiting and pattern blocking:
case IncidentModelExtraction:
// Implement rate limiting to prevent further extraction
actions = append(actions, ContainmentAction{
Type: "EMERGENCY_RATE_LIMIT",
Description: "Implement emergency rate limiting",
Target: []string{"llm_api"},
})
// Block suspicious query patterns
actions = append(actions, ContainmentAction{
Type: "BLOCK_PATTERNS",
Description: "Block query patterns indicative of model extraction",
Target: []string{"api_gateway"},
})
}
// Execute containment actions
for _, action := range actions {
if err := lir.containment.ExecuteAction(action); err != nil {
return fmt.Errorf("containment action %s failed: %w", action.Type, err)
}
incident.ContainmentActions = append(incident.ContainmentActions, action)
}
return nil
}
Here’s the notification requirement determination based on regulatory compliance:
func (lir *LLMIncidentResponse) determineNotificationRequirements(assessment *ImpactAssessment) []NotificationRequirement {
var requirements []NotificationRequirement
// GDPR notification requirements (72 hours for authority, immediate for high-risk to individuals)
if assessment.ComplianceImpact.GDPRBreach {
requirements = append(requirements, NotificationRequirement{
Recipient: "data_protection_authority",
Timeline: 72 * time.Hour,
Required: true,
Content: "GDPR breach notification to supervisory authority",
})
if assessment.DataImpact.HighRiskToIndividuals {
requirements = append(requirements, NotificationRequirement{
Recipient: "affected_individuals",
Timeline: time.Hour, // As soon as reasonably possible
Required: true,
Content: "GDPR high-risk breach notification to data subjects",
})
}
}
// HIPAA breach notification (60 days to OCR, 60 days to individuals)
if assessment.ComplianceImpact.HIPAABreach {
requirements = append(requirements, NotificationRequirement{
Recipient: "hhs_ocr",
Timeline: 60 * 24 * time.Hour,
Required: true,
Content: "HIPAA breach notification to Office for Civil Rights",
})
}
return requirements
}
This specialized incident response framework addresses the unique challenges of LLM security incidents. Unlike traditional breaches that might involve stolen files, LLM incidents can involve model behavior modification, prompt injection attacks, or subtle data leakage that’s difficult to detect and quantify.
Conclusion: Security as a Foundation, Not an Afterthought
Securing LLM APIs that handle sensitive data is fundamentally different from traditional API security. The challenges extend far beyond network security and authentication—they encompass AI-specific attack vectors, complex regulatory compliance, and the inherent tension between AI functionality and data protection.
The solutions we’ve explored address the full spectrum of LLM security challenges:
- Intelligent data classification that automatically applies appropriate security controls based on data sensitivity
- Multi-layer encryption that protects data without destroying AI functionality
- Zero-trust architecture that considers context, risk, and data classification for every access decision
- Comprehensive audit systems that create compliance-grade trails for regulatory scrutiny
- LLM-aware security controls that detect prompt injection, model extraction, and other AI-specific attacks
- Intelligent compliance routing that ensures data never crosses inappropriate jurisdictional boundaries
- Specialized incident response that addresses the unique challenges of AI security breaches
The fundamental insight is that LLM security requires a security-first approach to architecture. Organizations that try to “add security later” discover that their design decisions have created insurmountable compliance and security challenges. Data flows, model interactions, and external dependencies must all be designed with security and compliance as primary constraints.
Recent regulatory developments have only increased the stakes. The EU AI Act, emerging state privacy laws, and sector-specific regulations like HIPAA and PCI DSS are all adapting to address AI-specific risks. Organizations that build comprehensive security frameworks now will be well-positioned for these evolving requirements.
Perhaps most importantly, security in LLM systems isn’t just about preventing breaches—it’s about maintaining trust. When users share sensitive information with AI systems, they’re placing extraordinary trust in the organization’s ability to protect that data. A single security incident can destroy years of trust-building and permanently damage an organization’s reputation.
Building truly secure LLM APIs requires expertise that spans traditional cybersecurity, AI/ML engineering, regulatory compliance, and incident response. The technical complexity is matched by operational complexity—monitoring systems need to understand AI behavior patterns, incident response teams need to understand model extraction attacks, and compliance teams need to understand the implications of sending data to external LLM providers.
Building production-ready LLM systems requires navigating dozens of architectural decisions, each with far-reaching implications. At Yantratmika Solutions, we’ve helped organizations avoid the common pitfalls and build systems that scale. The devil, as always, is in the implementation details.